Alfresco ECM no viene con antivirus de serie, al igual que otras aplicaciones y programas como puede ser OpenOffice.org, etc. dejando esta tarea al sistema operativo y las soluciones antivirus elegidas.
La solución de usar un antivirus directamente sobre Alfresco plantea varias soluciones cada una con sus pros y sus contras así como el impacto en el sistema que puede ser mayor o menor.
.
Se pueden plantear por tanto varias soluciones de escaneo con los documentos subidos a Alfresco, que pueden ser:
1. Escaneo del repositorio localizando el fichero infectado directamente y dejando a posteriori la localización del NodeRef.
2. Escaneo bajo demanda al subir un documento, haciendo para ello que Alfresco ECM redirija el contenido hacia un antivirus que permita la lectura de un stream de datos.
Ambas soluciones son viables en Alfresco aunque su función es distinta, en la primera se escanea todo el repositorio, dejándose generalmente para tareas nocturnas o de fin de semana y aseguran tener un repositorio saneado con el tiempo. Esto causa impacto en los discos que cada cierto tiempo tienen que realizar la tarea de principio a fin y que puede ser muy larga dependiendo del tamaño del repositorio.
La segunda solución es limpia y permite que cualquier documento subido a Alfresco ECM haya sido previamente escaneado, bloqueando si es necesaria, su subida si se detecta un código maligno. Esta solución impacta directamente a la hora de la subida del documento pero nos asegura que los archivos subidos estén limpios sin tener que ser examinados posteriormente.
Una solución muy completa es la de unir ambas soluciones de forma que siempre sean escaneados los documentos al ser subidos y creados en Alfresco ECM y a su vez, que cada cierto tiempo se compruebe la “salud” de los documentos pasando un escaneo completo ya que además se escanearán con la última actualización del antivirus lo que puede detectar documentos con virus que inicialmente no fueron detectados.
— Una primera solución —
Para la primera solución, a su vez, se puede abordar desde distintas perspectivas, bien desde un plano más externo a Alfresco ECM y otro directamente desarrollando parte de la solución como una extensión de este.
En cualquier caso hay que elegir una solución antivirus que pueda servirnos para estos propósitos. En mi caso he elegido la solución ClamAV ya que permite muchas formas de interactuar, es OpenSource y podemos usarlo en varias plataformas (Linux, BSD, AIS, Solaris, etc.)
Para instalar ClamAV solo hay que instalarlo vía apt-get/aptitude, yum, etc. o bien bajando el fichero directamente y compilándolo, generalmente con la secuencia:
./configure
make
make install
Una vez instalado (en el servidor, se entiende) podemos hacer uso del comando “clamscan” para escanear el repositorio. (NOTA: No es objetivo de este post la configuración de clamav, freshclam, etc.)
El uso de clamscan es muy sencillo, básicamente hay que poner las opciones necesarias y el directorio/fichero a escanear. Aquí vamos a usar las opciones de visualizar solo los ficheros infectados y que además sea de forma recursiva.
Un ejemplo:
clamscan -i -r /alfresco/alf_data/
Bien, hasta aquí correcto, nos listará los virus encontrados, pero ahora necesitamos saber a qué documento de alfresco corresponde en su entorno. Como sabemos, en Alfresco, ni siquiera el nombre del documento es correcto para poder localizarlo, en todo caso podría ser si conocemos la ruta completa, aunque no sería lo mejor; pero si podemos usar el UUID o también llamado nodeRef.
Aquí podemos usar también varias formas, bien haciendo llamadas RESTful/SOAP a WebServices o WebScripts de Alfresco ECM en el que hay que extenderlo para poder realizar las llamadas necesarias y que este nos devuelva los valores o bien realizar las acciones que necesitamos; o usar directamente consultas SQL a la base de datos utilizada. En este primer caso vamos a usar una consulta SQL hacia nuestra instalación en MySQL.
La consulta podría ser algo asi:
SELECT alf_node.uuid
FROM alf_node_properties
INNER JOIN alf_node
ON alf_node.id = alf_node_properties.node_id
INNER JOIN alf_qname
ON alf_qname.id = alf_node_properties.qname_id
WHERE alf_node_properties.node_id =
(SELECT alf_node_properties.node_id
FROM alf_content_url
INNER JOIN alf_content_data
ON alf_content_url.id = alf_content_data.content_url_id
INNER JOIN alf_node_properties
ON alf_content_data.id = alf_node_properties.long_value
INNER JOIN alf_qname
ON alf_qname.id = alf_node_properties.qname_id
WHERE alf_content_url.content_url = ‘${FUID}’
AND alf_qname.local_name = ‘content’)
AND alf_qname.local_name = ‘name’;
Donde ${FUID} es la localización física del fichero en el contentstore o File Unique IDentifier, lo que Alfresco ECM llama normalmente contentUrl.
Bien, entonces, ¿Cómo podríamos hacer para que si un fichero es localizado con un virus, nuestro sistema Linux realice una llamada a Alfresco para que, por ejemplo lo renombre, ponga un aviso en el título, envíe correos electrónicos, etc.?
Para esto vamos a usar además un comando más, el comando wget (o curl si se prefiere) que puede realizar peticiones GET a un servidor para poder llamar a Alfresco ECM via RESTful y realizar una llamada al WebScript necesario.
Lo primero es el script que usaremos dentro del cron del sistema operativo (en este caso realizado para Linux CentOS con bash):
——————– alfviral.sh
#!/bin/bash
# Variables de configuración
#
ALFUSER=admin
ALFPASSWD=admin
ALFRESCO_URL=http://localhost:8080/alfresco
DIR_ROOT=/home/alfresco/alfresco-enterprise-3.3.4/alf_data
USERNAME=alfresco
PASSWD=alfresco
DATABASE=alfresco_enterprise_334
HOST=localhost
PORT=3306
PROG=$0
PROGDIR=`dirname «$PROG»`
SCANRES_FILE=scanres.txt
NODEREFS_FILE=noderefs.txt
DOCNAMES_FILE=docnames.txt
# Crea lista de ficheros infectados
#
echo «Creando lista de ficheros infectados…»
rm -f ${PROGDIR}/${SCANRES_FILE} 2>/dev/null
CONTENTSTORE=${DIR_ROOT}/contentstore
clamscan -i -r ${CONTENTSTORE} | awk -F: ‘$1~/.bin/{print «store:/»$1}’ | sed s:${CONTENTSTORE}::g >${PROGDIR}/${SCANRES_FILE}
if [ ! -s ${PROGDIR}/${SCANRES_FILE} ]
then
echo «No hay ficheros infectados.»
exit 0
fi
# Crea lista de NodeRefs de los ficheros
#
echo «Creando referencias NodeRefs de los FUID…»
rm -f ${PROGDIR}/${NODEREFS_FILE} 2>/dev/null
for FUID in $(cat ${PROGDIR}/${SCANRES_FILE})
do
mysql -u${USERNAME} -p${PASSWD} -D${DATABASE} -h${HOST} -P${PORT} –skip-column-names –raw –silent >>${PROGDIR}/${NODEREFS_FILE} <
SELECT alf_node.uuid
FROM alf_node_properties
INNER JOIN alf_node
ON alf_node.id = alf_node_properties.node_id
INNER JOIN alf_qname
ON alf_qname.id = alf_node_properties.qname_id
WHERE alf_node_properties.node_id =
(SELECT alf_node_properties.node_id
FROM alf_content_url
INNER JOIN alf_content_data
ON alf_content_url.id = alf_content_data.content_url_id
INNER JOIN alf_node_properties
ON alf_content_data.id = alf_node_properties.long_value
INNER JOIN alf_qname
ON alf_qname.id = alf_node_properties.qname_id
WHERE alf_content_url.content_url = ‘${FUID}’
AND alf_qname.local_name = ‘content’)
AND alf_qname.local_name = ‘name’;
q
STOP
done
if [ ! -s ${PROGDIR}/${NODEREFS_FILE} ]
then
echo «Â¡No se han encontrado referencias a los ficheros!»
exit 1
fi
# Lanza las llamadas a Alfresco hacia el webscript
#
echo «Llamando a Alfresco…»
rm -f ${PROGDIR}/${DOCNAMES_FILE} 2>/dev/null
ALF_TICKET=`curl «http://localhost:8080/alfresco/service/api/login?u=${ALFUSER}&pw=${ALFPASSWD}» | grep TICKET_ | sed ‘s:::g’ | sed ‘s:::g’`
for NODEREF in $(cat ${PROGDIR}/${NODEREFS_FILE})
do
curl «${ALFRESCO_URL}/service/protect/alfviral?nref=${NODEREF}&alf_ticket=${ALF_TICKET}» >>${PROGDIR}/${DOCNAMES_FILE}
echo «» >>${PROGDIR}/${DOCNAMES_FILE}
done
——————– alfviral.sh
Y en segundo lugar crear un WebScript que realice las tareas necesarias:
——————– alfviral.get.desc.xml
<webscript> <shortname>Alfresco Virus Alertshortname>
<description>Alfresco Virus Alertdescription>
<url>/protect/alfviral?nref={nref}url>
<format default=»text»>extension</format>
<authentication>user</authentication>
<transaction>required</transaction>
webscript>
——————– alfviral.get.desc.xml
——————– alfviral.get.js
// chequeo de parámetros
if (args.nref == undefined || args.nref.length == 0)
{
status.code = 400;
status.message = «Es necesario indicar el nref.»;
status.redirect = true;
}
else
{
// buscar el documento por su nodeRef
var nodes = search.luceneSearch(«ID:»workspace://SpacesStore/» + args.nref + «»»);
// renombrar el documento
var name_infected = «»;
name_infected = nodes[0].name;
if (name_infected.indexOf(«_INFECTADO») == -1)
{
nodes[0].name = name_infected + «_INFECTADO»;
nodes[0].save();
if (logger.isLoggingEnabled())
logger.log(«El documento: » + nodes[0].name + » ha sido renombrado por estar infectado.»);
}
model.name_infected = nodes[0].name;
}
——————– alfviral.get.js
——————– alfviral.get.text.ftl
${name_infected}
——————– alfviral.get.text.ftl
——————– alfviral.get.html.400.ftl
${status.message}
body>
html>
——————– alfviral.get.html.400.ftl
Poniendo la llamada en nuestra crontab podemos escanear periódicamente nuestro repositorio y actuar en consecuecia.
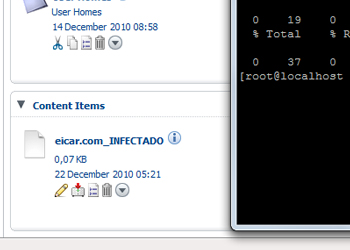
En este caso, simplemente se han renombrado los documentos infectados, como puede verse en la imagen:
Para la segunda entrega seguiremos abordando nuevas posibilidades para mantener «sano» nuestro repositorio.
¡Ah!, y FELIZ NAVIDAD A TODOS