Verión: 1 – Revisión: 0 – Publicación: 4/10/2011 – Última modificación: 4-oct-2011
Introducción
La instalación de Alfresco ECM requiere de una requisitos previos así como unas acciones posteriores para que el sistema comience a funcionar correctamente y se mantenga “sano” surante todo el tiempo que esté gestionando la documentación y registros. Este artículo pretende ser solamente un compendio de consejos y buenas prácticas y por tanto se irá modificando y ampliando en la medida de lo posible.
El ciclo de instalación, configuración y mantenimiento de Alfresco ECM comprende las siguientes fases:

Fase de preparación
1. Diseñar tanto la arquitectura física como la arquitectura lógica antes de comenzar la instalación, si bien pueden usarse diagramas mixtos, es preferible realizar estos diseños por separado lo que nos dará también la posibilidad de generar lo sentregables para los distintos departamentos (comunicaciones y hardware, sistemas, etc.)
2. Utilizar arquitecturas de 64 bits preferentemente, tanto a nivel de Hardware como Software (Sistema Operativo, Máquina Virtual de Java, etc.). Esto es muy importante en la medida en que en sistemas de 32 bits. se limita a nivel de direccionamiento de memoria principalemente.
3. Usar procesadores de doble núcleo como mínimo y procesadores de 2,5GHz. en adelante.
4. Usar la matriz de compatibilidad establecida por Alfresco para la instalación de todos los componentes: http://www.alfresco.com/services/subscription/supported-platforms/
5. Adecuar la instalación a la arquitectura planteada y verificar la disponibilidad de recursos (NAS/SAN, SGDB,…) y que estos están disponibles, que son montados en el inicio de la máquina o al menos antes de arranque de Alfresco ECM.
Ejemplos (en Linux/Unix/MacOS X):
Comprobar las unidades montadas para verificar su existencia: mount
Verificar la correcta escritura: touch prueba
Comprobar que el servidor de la SGDB está funcionando: ping servidorsgdb
6. Verificar la disponibilidad de los puertos que son necesarios para la instalación. Algunos puertos importantes para Alfresco son los siguientes:
- a. FTP: TCP 21 (se recomienda desconectar)
- b. SMTP: TCP 25
- c. SMB / NetBT: UDP 137,138, TCP 139,445 (para determinados entornos no es aconsejable)
- d. IMAP: TCP 143
- e. SharePoint Protocol: TCP 7070
- f. Tomcat Administration: TCP 8005
- g. HTTP: TCP 8080 (Tomcat, JBoss,…) / 9080 (para WebSphere) /…
- h. RMI: TCP 50500
Ejemplos (en Linux/Unix/MacOS X):
Comprobar la existencia del puerto SMTP: telnet servidoralfresco 25
Otra forma de comprobar que el puerto está abierto: nmap -P0 -p T:21,25,110,8080 servidoralfresco
Puertos abiertos en el mismo servidor: netstat -putan
7. Verificar la correcta comunicación tanto a nivel de fiabilidad como de estabilidad, verificar la latencia y rapidez de las transferencias:
- a. Conexión con el SGBD.
- b. I/O del disco que almacena los índices de Lucene.
- c. I/O del disco que almacena el repositorio.
- d. Conectividad entre los nodos (clúster).
- e. Conectividad con servidor NTP.
Ejemplos (en Linux/Unix/MacOS X):
Comprobar la transferencias a discos locales cada 2 segundos: iostat -w 2
Visualizar las estadísticas de red cada 2 segundos: netstat -s -p tcp -w 2
8. Comprobar la configuración con el SGDB con un DBA certificado así como la configuración del sistema de almacenamiento del repositorio con un experto certificado en el sistema de archivo usado (GFS, OCFS, VxFS, etc.). Es muy aconsejable que tanto la SGBD como el lugar donde se aloja el repositorio se conecten mediante “fibre channel” para evitar excesivas latencias y lentitud en las transacciones.
9. Usar Alfresco Environment Validation Tool (Alfresco EVT) para validar el entorno (http://code.google.com/p/alfresco-environment-validation/)
Fase de instalación
1. Crear una plantilla estándar adecuada al tipo de instalación y entorno con “checks” de control de las tareas. Es importante que los técnicos que instalen los sistemas, rellenen correctamente estas hojas e indiquen todas las incidencias que encuentran.
2. Verificar los parámetros para la instalación, espacio disponible en discos, memoria RAM de los equipos y memoria Heap/Stack/Perm a usar para la JVM según el fabricante soportado (SUN, ORACLE, etc.), descriptores posibles, máximas conexiones del servidor de aplicaciones así como de firewalls y proxies puestos delante de Alfresco ECM.
Recomendaciones básicas de memoria para producción:
– Heap (-Xmx): 4G
– Pila (-Xss): 256k
– Perm (-XX:MaxPermSize): 256m
Ejemplos (en Linux/Unix/MacOS X):
Kernel: uname -a
Datos del sistema: cat /proc/cpuinfo
Verificar memoria: free
Procesos java arrancados: jps -v
Procesos java arrancados: ps -fea | grep java
3. Utilizar las recomendaciones de Alfresco para la ubicación de los archivos:
- a. ${TOMCAT_HOME}/shared/classes/extension/alfresco
- b. ${WEBSPHERE_HOME}/lib/alfresco
- c. ${JBOSS_HOME}/conf/alfresco
4. NO incluir nunca ficheros de configuración en el despliegue de Alfresco ECM excepto por parte de módulos.
5. Usar SIEMPRE módulos (mmt) para la instalación de nuevas funcionalidades, personalizaciones y configuraciones de Alfresco ECM.
6. Usar las recomendaciones de Alfresco para la creación de ficheros de propiedades y XML y el uso de las normas estándar para la lectura de ficheros de configuración de Spring Framework.
7. Puede utilizarse NFS con SAN para entornos clúster de repositorio compartido (solo a partir de la versión 3.4 según Alfresco) aunque es recomendable la utilización de sistemas de ficheros de clúster/concurrencia como GFS, OCFS, VxFS, etc.
8. Los índices de Apache-Lucene deben ir siempre en el sistema local o en su defecto en NAS. A partir de la versión 4 de Alfresco ECM podrá utilizarse Solr.
9. Es preferible tener en el “extension” una copia de log4j.properties como custom-log4j.properties para gestionar la salida de información de los logs.
10. Aunque no es parte de Alfresco ECM, hay que medir cuidadosamente los aplicativos que interactúan con este respecto a seguridad:
- a. Uso de SSL (HTTPS) para asegurar canales de comunicación. Si es posible, también entre los propios elementos de Alfresco ECM, como Alfresco Share y el repositorio.
- b. Configuración de sistemas de autenticación externa mediante CAS, AD-Kerberos, NTLM, etc. y usar Single Sign On (SSO) en la medida de lo posible.
- c. Usar puertos por encima del 1024 y usuario “no root” en las instalaciones en sistemas Linux/Unix.
11. No es recomendable balancear los protocolos TCP como CIFS/SMB, FTP y NFS que Alfresco ECM ofrece como servicios debido a problemas de bloqueos en JLan hasta aviso de Alfresco ECM y por lo menos hasta la versión actual (3.4.x). Sí es posible balancear HTTP/HTTPS y WebDAV. Una posible arquitectura siguiendo esta recomendación sería la siguiente:
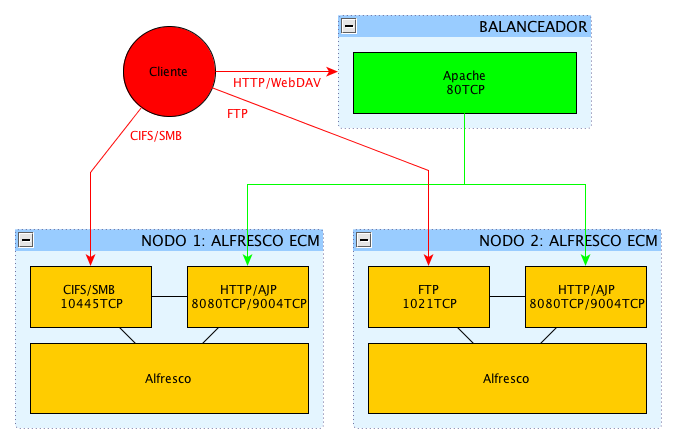
12. NO USAR JAMÁS EL USUARIO ROOT, crear un usuario tomcat, alfresco, jboss, etc. con los privilegios apropiados (acordarse de que en máquinas con Linux/Unix/MacOS X no pueden usarse puertos por debajo del 1024 por defecto).
13. Es muy aconsejable que siempre se realicen 3 tipos de instalación, una para la parte de desarrollo y personalización, otra para preproducción o “Quality Service” que sirva para realizar pruebas antes de desplegar en producción, y una tercera instalación para producción. El entorno de desarrollo puede ser “no cluster” siempre y cuando no dependa dicho desarrollo de elementos própios de este. El entorno de preproducción y producción deben ser totalmente idénticos excepto en el tema de arquitectura hardware, es decir, puede ser un entorno con máquinas virtuales en preproducción y con máquinas físicas o virtuales con mayor asignación de recursos en producción. Así mismo, la carga de datos entre preproducción y producción tiene que ser lo más parecida posible, siempre al menos de un 50% de carga entre uno y otro para no tener problemas posteriores en cuanto a límites.
Fase de configuración y tuning
1. Comprobar que la configuración de la codificación tanto en el SO, la SGDB, sistema de ficheros y JVM están en UTF-8. Ejemplos:
- a. En JVM de SUN y JRockit de IBM: -Dfile.encoding=UTF8
- b. En MySQL (my.cnf): default-character-set=utf8
- c. En Oracle, debe realizarlo un DBA.
2. Usar autenticación con Single Sign On (SSO) en lo posible a través de AD-Kerberos o CAS siendo CAS el recomendable actualmente.
3. Establecer los parámetros de monitorización en el arranque (JMX)
Ejemplo:
Para monitorizar con jconsole: jconsole service:jmx:rmi:///jndi/rmi://servidoralfresco:50500/alfresco/jmxrmi
4. Verificar parámetros de configuración y optimización del SGBD siempre a través de personal DBA certificado. Por ejemplo:
- a. MySQL: ANALYZE
- b. PostgreSQL: VACUUM y ANALYZE
- c. Oracle: Dependiente de la versión, debe realizarse por un DBA.
- d. MS-SQL Server: ALTER INDEX REBUILD, UPDATE STATISTICS
- e. DB2: REORGCHK, RUNSTATS
5. Utilizar los parámetros de optimización aconsejados por Alfresco:
- a. Ajustar pool de conexiones de Alfresco, se recomiendan 225 en adelante para el uso de protocolo CIFS/SMB. En WebSphere, Tomcat, Jboss, etc. Se pueden gestionar las conexiones a través de JNDI. En este caso, hay que tener en cuenta si el que controla los parámetros de conexiones máximas, mínimas, tiempos de espera para cierre de conexiones, etc. es Alfresco ECM o el mismo servidor de aplicaciones. Por ejemplo para WebSphere se pueden modificar los valores correspondientes desde la Consola de administración, en Recursos->JDBC->Orígenes de datos->(origen)->Propiedades de la agrupación de conexiones.
db.pool.max=275
- b. Deshabilitar el uso de máximo de conexiones abiertas, es decir, no espera un tiempo en los que la conexión no responde para cerrarla. Igual que en el punto anterior, hay que modificarlo en la consola de administración de WebSphere o ficheros necesarios en otros servidores de aplicaciones.
db.pool.idle=-1
- c. Esteblecer un tamaño de consultas (registros) mayor al establecido por defecto (10 registros).
hibernate.jdbc.fetch_size=150
- d. Desactivar la parte de almacenamiento de transacción atómica para los índices y las transacciones de indexación “atómicas”, SOLO EN EL CASO DE IMPORTACIONES Y SUBIDAS MASIVAS DE DOCUMENTOS.
lucene.maxAtomicTransformationTime=0
index.tracking.disableInTransactionIndexing=true
- e. Si no se van a usar “quotas” de espacio, se aconseja desconectarlas ya que suponen tiempo de cálculo.
system.usages.enables=false
- f. Usar JodConverter en lugar de la integración directa con OpenOffice.org deshabilitando esta última ya que si no Alfresco levantará dos instancias de OpenOffice.org. También es aconsejable usar un servidor independiente para realizar todas las conversiones.
ooo.enabled=false
jodconverter.enabled=true
- g. En clúster usar JGroups con conexiones TCP (para controlar mejor las conexiones).
- h. En clúster usar el “tracking” cada 5 segundos.
index.tracking.cronExpression=0/5 * * * * ?
- i. En sistemas con muchos documentos y consultas Apache-Lucene muy genéricas, el resultado puede contener muchas filas y tardar mucho tiempo. Para evitar que salgan menos filas de las solicitadas hay que adaptar los parámetros system.acl.maxPermissionCheckTimeMillis y system.acl.maxPermissionChecks, pe. Para la salida de hasta 30000 filas cuya consulta dura menos de 5 minutos sería:
system.acl.maxPermissionCheckTimeMillis=300000
system.acl.maxPermissionChecks=30000
- j. Si es necesario indexar todo el contenido del documento y este tiene más de 10000 términos, hay que ajustar el valor lucene.indexer.maxFieldLength para que indexe todo el contenido. Por ejemplo, para que indexe contenidos con hasta 150000 palabras:
lucene.indexer.maxFieldLength=150000
- k. Configurar correctamente y verificar su acceso a las utilidades utilizadas por Alfresco ECM:
ImageMagick
Pdf2swf
OpenOffice.org
- l. Realizar pruebas de carga y estrés antes de la puesta a producción mediante herramientas especializadas, p.e. JMeter.
- m. Adaptar valores de EHCache a los nodos, usuarios, permisos (ACLs), tickets de autenticación, etc. para que no se llene.
Desarrollo y personalización
Extensión del modelo de datos
1. Usar la indexación por tokens en los casos necesarios, p.e. para metadatos que usan caminos, códigos o palabras sin significado semántico es mejor usar solamente la indexación por cadenas (strings).
Por ejemplo, si se tiene un metadato llamado “sección” que almacena una sección en particular como valor único, se podría definir como:
d:text
true
false
false
2. Utilizar ficheros independientes por modelo de datos así como de prefijos para clarificar los desarrollos.
3. NO usar nunca los modelos de ejemplo que vienen en Alfresco ECM.
4. Es preferible usar Aspectos a Tipos e intentar crear tipos básicos heredados de los que Alfresco ECM incluye por defecto.
5. Usar solamente los metadatos que van a ser usados en búsquedas en el gestor documental directamente y que tengan relevancia dentro de la gestión documental.
6. Usar restricciones donde hagan falta (CONSTRAINTS) y reutilizarlas.
7. Evitar en la medida de lo posible muchas asociaciones (ASSOCIATIONS), ya que Alfresco ECM no es un sistema relacional.
8. No cambiar el modelo original de Alfresco ECM bajo ningún concepto.
9. No eliminar modelos y aspectos si no se tiene total seguridad de que no han sido usados nunca.
10. Evitar complejidades innecesarias en los modelos así como excesiva profundidad en la estructura.
11. El modelo de datos dedicado a permisos y roles no puede ser movido del lugar del despliegue actualmente y hay que ser muy cauto a la hora de crear nuevos roles.
12. Se aconseja no modificar los roles actuales.
Interoperabilidad
1. Usar CMIS a través de RESTful principalmente (versión 3.4 en adelante) o en su defecto WebServices a través de SOAP para mantener la interoperabilidad, escalabilidad y estandarización.
2. Comunicarse a través de aplicaciones mediante tecnologías SOA. Capas intermedias de middelware, buses de integración, fachadas de servicios y sistemas centralizados de control.
3. Usar las AFC (Alfresco Foundation Classes) solo en casos muy específicos.
4. Si es necesario personalizar/desarrollar directamente en Alfresco ECM, es preferible realizarlo a través de WebScripts, Reglas/Acciones y Workflows en lugar de desarrollar directamente clases Java.
5. Es desaconsejado el uso de JCR ya que está obsoleto.
WebScripts/JavaScripts – Surf
1. Incluir los ficheros de scripts en los lugares adecuados del extensión en lugar del despliegue o en su defecto crear un módulo de Alfresco ECM para instalarse de forma limpia usando el mmt (Module Management Tool) de Alfresco ECM.
2. Usar librerías comunes mediante “includes” y reutilizar código.
3. Realizar depuraciones mediante el depurador incluido en Alfresco ECM.
4. Evitar mucha recursividad al recorrer nodos ya que puede llenar la memoria de pila, o bien, ampliar el espacio de esta en la configuración.
5. Dirigir los desarrollos hacia la plataforma Spring-Surf.
WebServices
1. Evitar la transferencia de grandes ficheros mediante mensajes SOAP. Usar para ello el Servlet que incorpora Alfresco ECM.
2. Minimizar las transferencias de información en tareas reiterativas. Por ejemplo, es preferible la llamada a un WebScript que devuelva en formato JSON/Atom/Text la lista de usuarios que realizar N llamadas desde el WebService cliente.
Búsquedas y consultas
1. Adecuar los motores de búsqueda de Alfresco ECM al tipo de consulta y resultado requerido XPath/Lucene/CMIS-SQL.
2. Es recomendable ir hacia consultas vía CMIS (cmis-strict) para estandarizar lo máximo posible.
3. Intentar optimizar las consultas Lucene/CMIS para que devuelva pocos resultados.
Autenticación y seguridad
1. Usar alf_ticket como método de mantener sesiones autenticadas en lugar de el uso de autenticaciones usuario/contraseña contínuas, así como JSESSIONID para el caso de mantener rutas en balanceadores. Se recomienda legar el uso de autenticaciones a Alfresco ECM y sistemas dedicados a esta tarea como CAS, AD-Kerberos, etc.
2. Almacenar los datos “sensibles” de forma “ofuscada” o encriptada.
Mantenimiento
1. Monitorizar la JVM, Servidor de Aplicaciones y la instancia de Alfresco ECM mediante Jconsole/VisualVM, IBM WebSphere Console, etc.
2. Realizar seguimientos de tráfico entre los componentes de Alfresco ECM (WebClients y Repositorio, Alfresco y SGBD, etc.) para detectar grandes cargas, tráfico alto y cuellos de botella usando comandos como ntop, iostat, netstat, etc.
3. Reindexar todo cuando se hayan cambiado valores de configuración de Apache-Lucene así como si se detecta corrupción en los índices. Esto es muy importante para mantener estable el sistema. Se puede usar la consola de chequeo de índices de Alfresco ECM para reindexar por fechas, transacciones, etc. Por ejemplo: http://servidoralfresco:8080/alfresco/service/enterprise/admin/indexcheck
4. Estudiar las salidas (logs) constantemente prestando especial atención a mensajes de aviso (Warnings) y errores (Errors) y filtrando convenientemente:
Ejemplo:
Salida controlada de errores de log en un WebSphere: tail -2000f /opt/WebSphere/AppServer70/profiles/AppSrv01/logs/alfresco/SystemOut.log | grep ” E “
5. Utilizar herramientas como NAGIOS/ICINGA para monitorizar puertos, memoria, CPU, etc.
6. Usar sistemas de mensajes SMS y alertas de seguimiento en los sistemas en producción.
Bibliografía
Documentos y libros
Título: Alfresco Day Zero Configuration Guide.pdf
Autor: Peter Monks
Título: Administering_an_Alfresco_Enterprise_3_4_0_Production_Environment.pdf
Autor: Alfresco
Título: Escalabilidad y tuning.pdf
Autor: Toni de la Fuente
Título: Scale your Alfresco Solutions. Architecture, Design and Tuning Best Practices
Autor: Gabriele Columbro
Titulo: Alfresco Developer Guide
Autor: Jeff Potts
Blogs:
http://www.blyx.com
http://www.fegor.com
http://ecmarchitect.com/
Webs:
http://docs.alfresco.com
http://www.juntadeandalucia.es/xwiki/bin/view/MADEJA/ArqSIAlfresco

















